
 Ελληνικά
ΕλληνικάSearch Engine Oprimization
Search engines – The history of their evolution

Oct
To understand the way search engines, work today as best as possible, we need to go back many years in history and pinpoint important landmark dates, to meet important people thanks to whose vision, intelligence and work we enjoy the quality of service we have today.
It’s not easy to realize it but just about 20 years ago the internet was nothing like we know it today.
A list of links that were collected and maintained manually by humans.
Finding the information, you needed was a really difficult process which usually involved countless clicks on links, hoping that in the end we would end up in the right place.
So, let’s meet some of the people who paved the way and created a new perspective for millions of users around the world.
A perspective that made information and knowledge accessible to all, created new businesses and jobs and much more.
Many attribute the idea of the internet to engineer Vannevar Bush who in 1945 wrote an article entitled “As We May Think“, through this article Bush pushed the leading scientists of the time to create a – almost – unlimited, fast, reliable, scalable, associative memory retrieval and storage system.

Bush had the foresight to realize that technology was developing rapidly and that through technology people would have to find a way to record, store and then have easy access to retrieve the information accumulated and stored in such a system.
A little later in 1960, Gerard Salton, who is considered the “father” of modern search technology, conceived the idea of the “search engine” and developed the pioneering system for the time called “SMART». The SMART Information Retrieval System, as was the full name of the system.
The initials SMART stand for: System for the Mechanical Analysis and Retrieval of Text, some sources render the phrase as: Salton’s Magic Automatic Retriever of Text.
Whichever one we consider correct, the point does not change.
Salton wrote a book called “A Theory of Indexing” in which he mentions ideas for the use of statistical balancing, relevance algorithms while at the same time he presents his original tests, on which search is based on – to a large extent – to this day.
Around the same time, Ted Nelson, an American pioneer in information technology, philosopher and sociologist, creates a new project called “Xanadu.

Xanadu was intended to be a network of computers, which would store and display documents, while also providing the ability to edit them.
Ted coined the term Hypertext (text displayed on a computer screen or other electronic devices with references (hyperlinks) to other text to which the reader can directly access) and his work was certainly a large part of the inspiration for the creation of the World Wide Web (hence the well-known www).
In the late 1960s, an agency called “ARPANET” (Advanced Research Projects Agency Network) was born, which was part of the US Department of Defense.
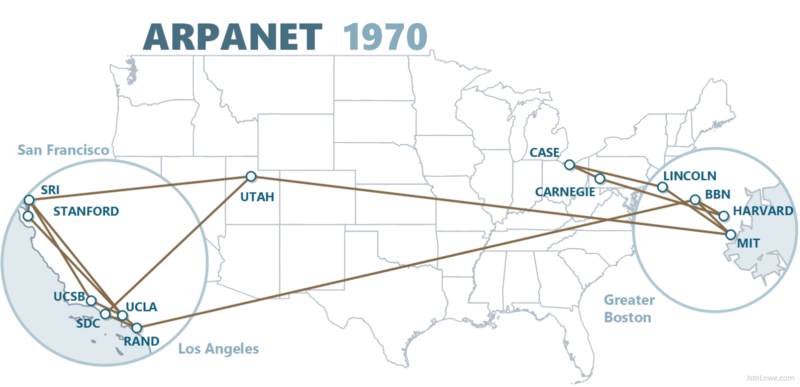
ARPANET was a computer network that allowed information to be transmitted over long distances.
To achieve this, they used leased telephone lines to transfer military information, as you may well realize it was essentially the beginning of the internet.
Below you can watch a mini documentary from 1972, about ARPANET.
It was almost 20 years from the appearance of ARPANET until we had the first search engine.
It was created by Alan Emptage and named “Archie” (from Archives).
“Archie” was able to retrieve files from a database by matching the user’s query using regular expressions
Archie did not use keywords to find relevant files as modern search engines do.
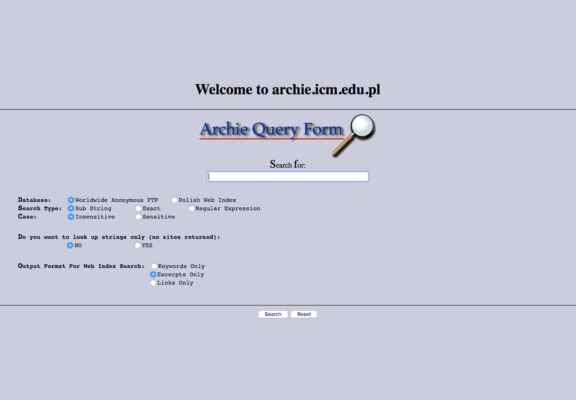
To use Archie effectively, you would need to know the name of the file you were looking for, as Archie did not index the contents of files, only the titles.
By 1992 Archie contained about 2.6 million files, and its service was processing about 50,000 queries every day, coming from thousands of users around the world.
As Archie’s popularity grew, two similar search engines, Veronica and Jughead, were created to index plain text files.
In 1991 Tim Berners – Lee created the World Wide Web based on the idea of Hypertext to facilitate information sharing and informing of researchers, it was then that the first website in the history of the World Wide Web was created which you can still visit today from here.

Of course, the display was not what it is today in the modern browsers we use (chrome, firefox, safari) if you want you can get the real feel of the website with the old line-mode browser and click on the Launch Line Mode Browser button.
In 1993 the first robot (bot or spider) was created, it was called World Wide Web Wanderer and its purpose was to measure the growth of the world wide web.
In its first update it recorded in a database, called “WANDEX”, the active URLs it found.
Later on, Wanderer ended up creating bigger problems than the ones it was trying to solve with the task it was assigned. It was visiting hundreds of pages in a day, all day long, causing problems to the servers hosting those pages which as a result “crashed”.
Let’s not forget that the infrastructure of the whole web was in very early stages, you could easily come up against whatever “limits” existed.
In response to the “evil” Wanderer, which was “dropping” servers and pages, “ALIWEB” was created which stood for: Archie – Like Indexing of the Web. To avoid the fate of the Wanderer, ALIWEB allowed webpages owners to submit them along with their website description, for ALIWEB to index them, so there was no longer need for a robot to search for data on its own and overload the network.
The main problem was that many owners did not know that they had to submit their website or how to do it.
You can read the second part of the article here
.